Understanding HashMap Data Structure With Examples
Imagine crumpling a paper document to the point that it's no longer readable. Hashing algorithm works in a similar fashion.

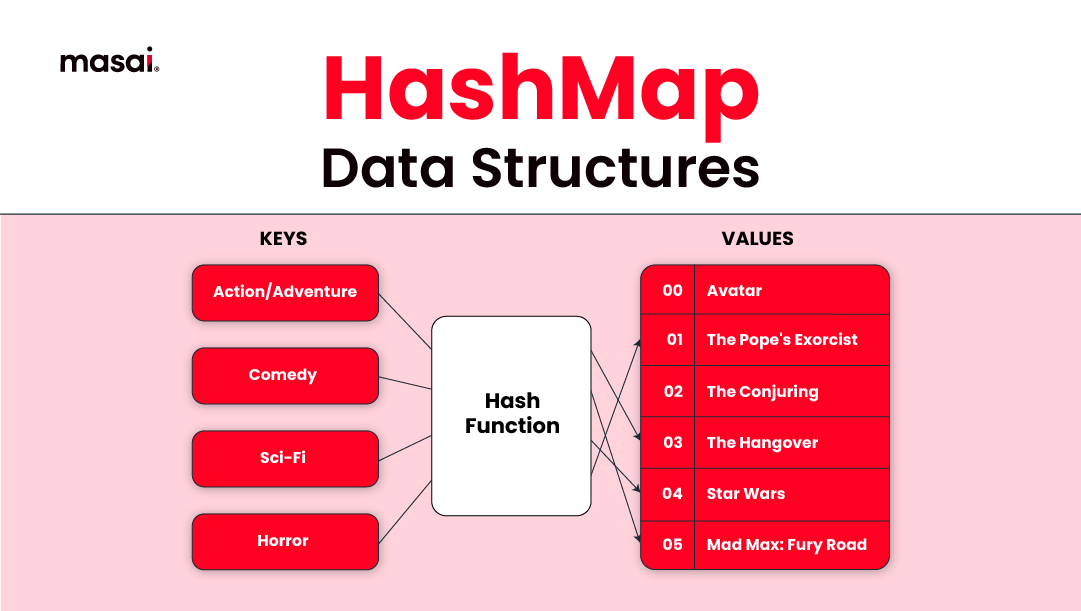
HashMaps explained to an 8-year-old:
Imagine you're in a giant toy store with hundreds of shelves filled with different toys. Now, you want to find your favorite superhero bobblehead. Would you go through every shelf? Or, would you simply ask the store manager who then quickly guides you to the exact shelf where your superhero bobblehead is located? The second option, right?
In this scenario, the store manager uses something similar to a hashmap to quickly find your toy.
So, What Exactly is a HashMap?
A hashmap is a data structure that pairs keys to values. It uses a hash function to calculate an index into an array of buckets, from which the desired value can be found. Simply put, it's like a real-world dictionary where you know the 'word' (key), and you quickly find its meaning' (value).
The primary operation it supports is a lookup: given a key (e.g., a person's name), finds the corresponding value (e.g., that person's telephone number). It uses a hash function to convert the key into the index of an array element (the 'bucket') where the corresponding value is stored.
The hash function takes a key of any size and shrinks it down into a small, fixed-size integer that serves as the index for the array. Ideally, the hash function distributes keys evenly across the array, so values are spread across evenly.
HashMap<String, String> superheroes = new HashMap<>();
superheroes.put("Peter", "Spiderman");
superheroes.put("Tony", "Iron Man");
superheroes.put("Bruce", "Batman");
Why do we need HashMaps?
While storing data in an array can be swift, taking O(1) time, the searching part isn't as quick - it takes at least O(log n) time. This time might seem small, but when dealing with a large amount of data, it can create hurdles, resulting in inefficiency.
What we need is a data structure that not only stores the data but can also retrieve it in constant time, meaning O(1) time. That's where the hashing data structure steps in.
As arrays store elements in a particular order, hashmaps don't follow any order.
They work by taking a key (like a book title) and running it through a hash function, which gives us a unique 'address' where we can find our data (like the book). This means no matter how big our data set gets, we can access data instantly - it's like magic!
So, in summary, we need hashmaps when we want speedy access to our data. They're particularly handy when dealing with large amounts of data, where searching through each piece one by one, like in an array, would be too slow.
Key Components of Hashing
Hashing is built upon two primary components:
Key: This is a unique identifier, akin to an ID, that we use to pull out the value that's connected to it. Each key is distinctive, which helps to keep our data organized and ensures that each piece of data is directly linked to a specific key.
Hash Function: Think of this as a magical formula or method that takes the key and transforms it into an address in memory where the corresponding data will be stored. It's a consistent function, which means for the same key input, it will always produce the same memory address.
int hashCode = key.hashCode(); // Convert the key to an integer (hashCode)
int index = hashCode % arrayLength; // Compute the index (bucket) for storing value
This might look oversimplified, but it captures the essence of a hash function: converting a key into an addressable index.
Understanding Hashing in Action
To understand how hashing works, it's useful to visualize it as a process:
When we want to store a piece of data, we first identify a unique key for that data. Then, we feed this key into our hash function. This function, being the magical formula it is, crunches the key and spits out a unique hashed value.
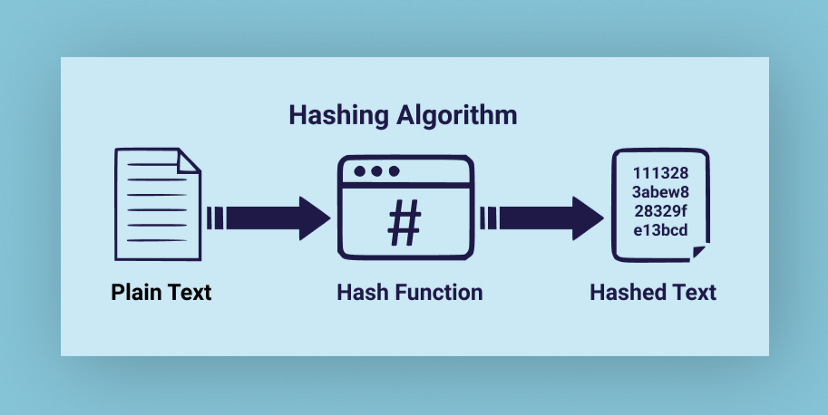
This hashed value is an index or an address in memory where we can store our corresponding data. So, we store our data at this hashed index.
Case in point, imagine crumpling a paper document to the point that it's no longer readable. Hashing algorithm works in a similar fashion.
Now, when it's time to retrieve the data, all we need is our key. We feed the key back into the hash function, and like a trusty old hound, it gives us the same unique hashed value (index) that it did before. We then go to this hashed index in memory and voila, we have our data!
But here's a problem: Collision in Hashing
Now, imagine there are two superheroes with the same name. Obviously, we can't place them in the same spot. This is what we call a collision in hashing, where two keys produce the same hashed value or index.
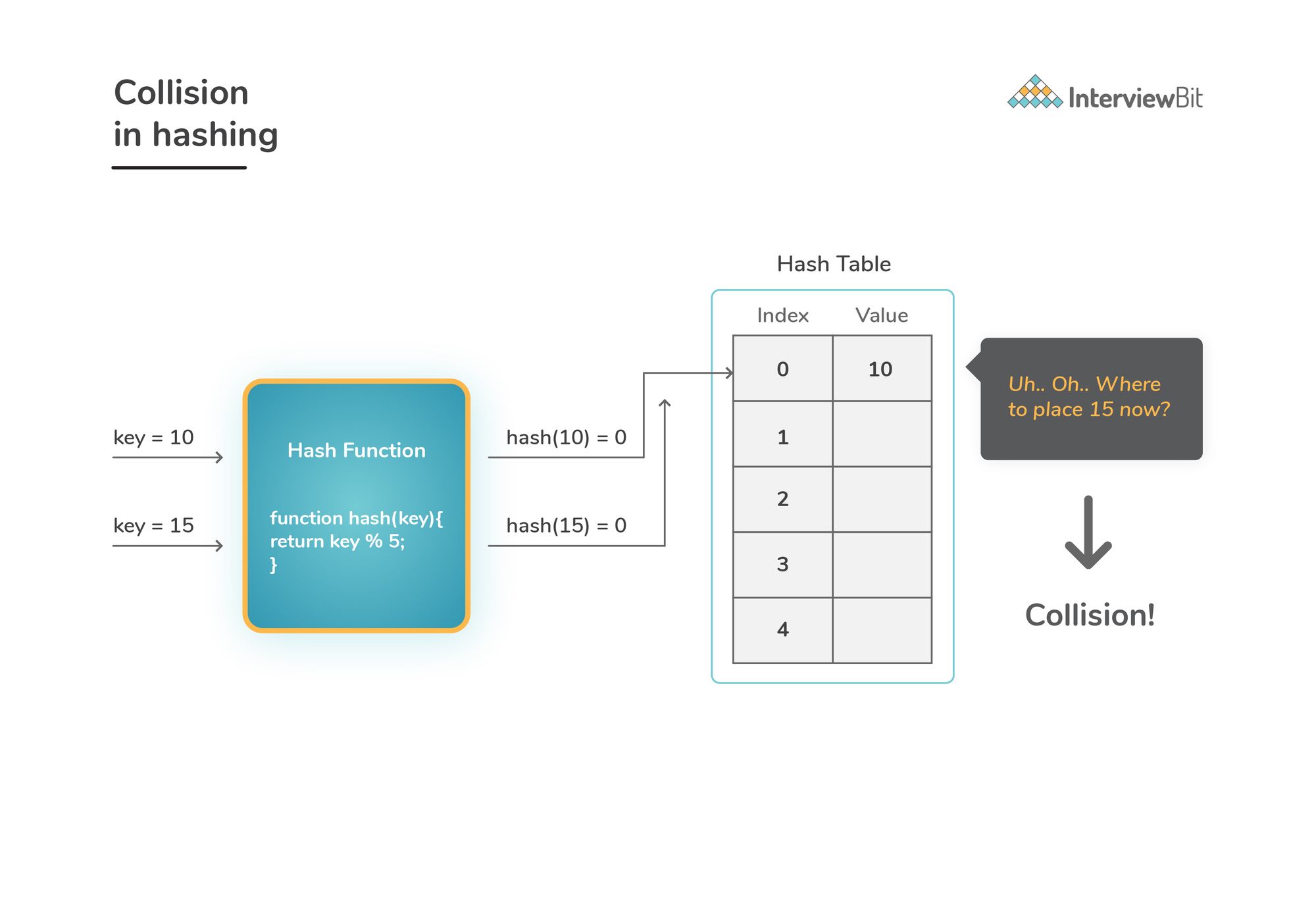
But worry not, developers have found smart ways to deal with this, such as 'Chaining' and 'Open Addressing'.
Chaining is where you let each spot on the shelf hold more than one item. You can picture it like a smaller shelf inside the original spot. This inner shelf can hold all superheroes that hash to the same spot.
Open Addressing, on the other hand, tells the latecomer superhero to find the next available spot. This is also known as 'probing'. The late superhero would look for the next spot or a spot based on a particular sequence until it finds an open spot.
(Here's an article that explains chaining and open addressing in detail)
Now, let's dive into the practical applications of hashmaps.
Applications of HashMaps
HashMaps have numerous applications and are used extensively in various types of programming, thanks to their speed and efficiency. Here are a few key areas where hashmaps shine:
1. Database Indexing: HashMaps can significantly speed up data retrieval, which is crucial in database operations. They are used to index large amounts of data. A unique key is assigned to each data record. This key is then hashed, and the data is stored at the resulting hash code's index.
2. Caching: They are used in caching data, which also boosts performance. For instance, when a function is called with the same value multiple times, the result can be stored in a hashmap after the first call. Subsequent calls can then retrieve the stored value from the cache instead of executing the entire function again.
3. Routers and DNS Resolution: Routers use hash tables to route internet traffic efficiently. Similarly, Domain Name System (DNS) resolvers use hashmaps to quickly find an IP address given a domain name.
4. Language Interpretation: HashMaps are used in compilers and interpreters for language translation. The variables and functions in a program are stored in a symbol table implemented as a hashmap. The compiler or interpreter can then quickly look up variables and functions as it processes the code.
Let's wrap things up with a brief look at the pros and cons of hashmaps.
Pros and Cons of HashMaps
Pros
- Fast data access: The ability to access data in O(1) average time complexity makes hashmaps incredibly efficient.
- Flexible keys: Unlike arrays, hashmaps can use any data type for keys, allowing for greater flexibility.
Cons
- Inefficient space usage: HashMaps typically allocate more space than needed to handle future entries (and avoid collisions), which can waste memory.
- Collision handling: While solutions for collisions exist, they can complicate the implementation and negatively impact performance in cases of many collisions.
Wrapping Up
Understanding the hashmap data structure and hashing is crucial for any budding programmer or computer scientist. Not only do they have a variety of applications, but their efficiency in accessing data makes them a popular choice for solving complex problems. Remember the secret superpower of our superhero shelf analogy—speed and efficiency!
That's all for now on hashmaps. Keep exploring, keep learning, and remember - coding isn't just about typing in a language your computer understands. It's about problem-solving, and data structures are one of your key tools in this endeavour.
On that note, we'll leave you with a comprehensive guide to data structures explained from scratch.
Cheers, and happy coding!
More in Data Structures:
Array Data Structure- Explained With Examples
Stack Data Structure - Explained With Examples
Queue Data Structure- Types & Applications
Linked List- Explained With Examples
Tree Data Structure- Types, Operations, Applications
Graph- Explained With Examples
Array vs Linked List[When to use What]
Applications of Queue Explained
Applications of Array Explained