12 Must-Know Algorithms For Programmers
Algorithms can simply be considered recipes. Take for example the recipe for baking a cake, or the process of finding words in a dictionary.


If you are planning to sit for an interview, then this article is your guide to the best algorithms you must know as a programmer.
Algorithms can simply be considered recipes. Take for example the recipe for baking a cake, or the process of finding words in a dictionary.
Let’s say you were a class monitor and you have to collect test papers from all the students and sort them according to their roll numbers.
You divide the papers into equal halves and give the other half to your friend. Then, both of you sort your halves according to roll numbers. In the end, you just put together both of your sets one sheet after the other, and voila! It’s done in half the time.
You might not have known but you used the merge sort in this case, one of the most important sorting algorithms out there.
This is also known as the ‘divide and conquer approach'.
That’s the power of algorithms. But, what exactly are they?
Algorithms can simply be considered recipes. Take for example the recipe for baking a cake, or the process of finding words in a dictionary. You can follow multiple ways to find a word but your objective always is to find it in the shortest possible time.
And, that remains the objective in almost all kinds of work we do. We want to do it fast and efficiently for better productivity and results. And that’s when we set up defined processes to carry out the work. (like the example you just witnessed above)
Algorithms are all around us. From traffic lights to social media, everything’s working on algorithms.
In computer science, algorithms are a set of instructions guiding the program to solve a problem or finish a certain task.
We’ve already learned in detail about data structures and the importance of storing data in a structured way. What happens after we store it? We feed algorithms to it depending on the output we want.
Both data structures and algorithms combine together to allow computers, smartphones, and other devices to function efficiently.
The objective of a programmer should be to use the best data structure that requires the least space, and the best algorithm that requires the least amount of time to perform a task.
In this article, we’ll be going through the most popular and commonly used algorithms and will try to understand how they break down problems.
Searching Algorithms
Searching algorithms are step-by-step procedures for finding specific data from any data structure where it is stored.
It is regarded as a fundamental computing procedure. When searching for data in computer science, the difference between a fast application and a slower one lies in the use of the appropriate search algorithm.
When we implement a search algorithm to a dataset, it returns a success or failure status which is typically represented by the Boolean True/False value. There are various search algorithms available and their performance depends on the type of data and the manner in which they’re being used.
Linear Search Algorithms
A linear search is by far the simplest approach while searching for an element within a data set. It analyses each element till it finds the right match, which is at the beginning of the data set until the end. The search is over and then terminated only once the algorithm locates the target element. If no match is found, the algorithm has to terminate its execution and then return an appropriate result. This search algorithm is quite easy to implement and very efficient in the following scenarios:
· When the list comprises fewer elements
· While searching for an individual element in an unordered array.
Imagine you have a stack of 15 books and you have to find a particular book. You go through each book cover one by one and find the book you wanted.
Or you have to find the king of hearts from a deck of cards. Here again, you go through each card one by one and stop when you find the card.
The linear search algorithm works in a similar fashion. It is the most basic and straightforward search algorithm; wherein all items are searched in a sequential manner. It returns true when the match is found, or else it keeps searching till the end of the dataset.
This search algorithm is only effective for relatively smaller datasets. Sequential search in huge datasets will have a high time complexity. (Know about time and space complexity here)
And since, we have to search each data item anyway, it’s the ideal method to work on unsorted data.
Binary Search Algorithm
A Binary search is usually used while performing highly efficient searches on datasets that are sorted. O(log2N) is the measured time complexity. This search repeatedly keeps dividing the portion of the list (in half). So that eventually, one portion contains the item until it is narrowed to one possible item. Some applications are:
- When we search the song name within a list of songs that are sorted.
- Used to debug in git through git bisect operations.
The best real-life example of a binary search algorithm would be when we look for a certain word in the dictionary. We don’t follow a sequential search as it would take much more time. Instead, we start searching randomly from the middle of the page. If the word is alphabetically lower than the words on that page, we ignore all the pages on the right and vice versa.
Similarly, in programming, the binary search algorithm searches data structures by intervals rather than taking a sequential approach. One thing to notice here is that it works only on sorted data. In the example above, all the words in the dictionary are already sorted alphabetically and that’s why implementing binary search is effective.
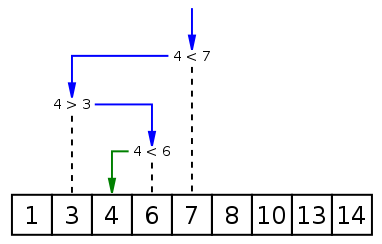
It repeatedly divides the search interval in half and reduces the time complexity to O(log N) in a sorted array.
Here are the basic steps to perform a binary search:
- Begin with the mid element of the whole array as a search key.
- If the value of the search key is equal to the item, returns an index of the search key.
- Or if the value of the search key is less than the item in the middle of the interval, narrow the interval to the lower half.
- Otherwise, narrow it to the upper half.
- Repeatedly check from the second point until the value is found or the interval is empty.
Jump Search
Jump Search also works on ordered lists/arrays, just like binary search.
The fundamental difference is in the process. The jump search technique makes a block and looks inside of it for the element. If the item is not present in the block, the block as a whole is moved. The size of the list determines the block size.
If the list size is n, the block size will be ‘route √n’
Interestingly, after a block has been located, it uses the linear search method to look for the item inside that block.
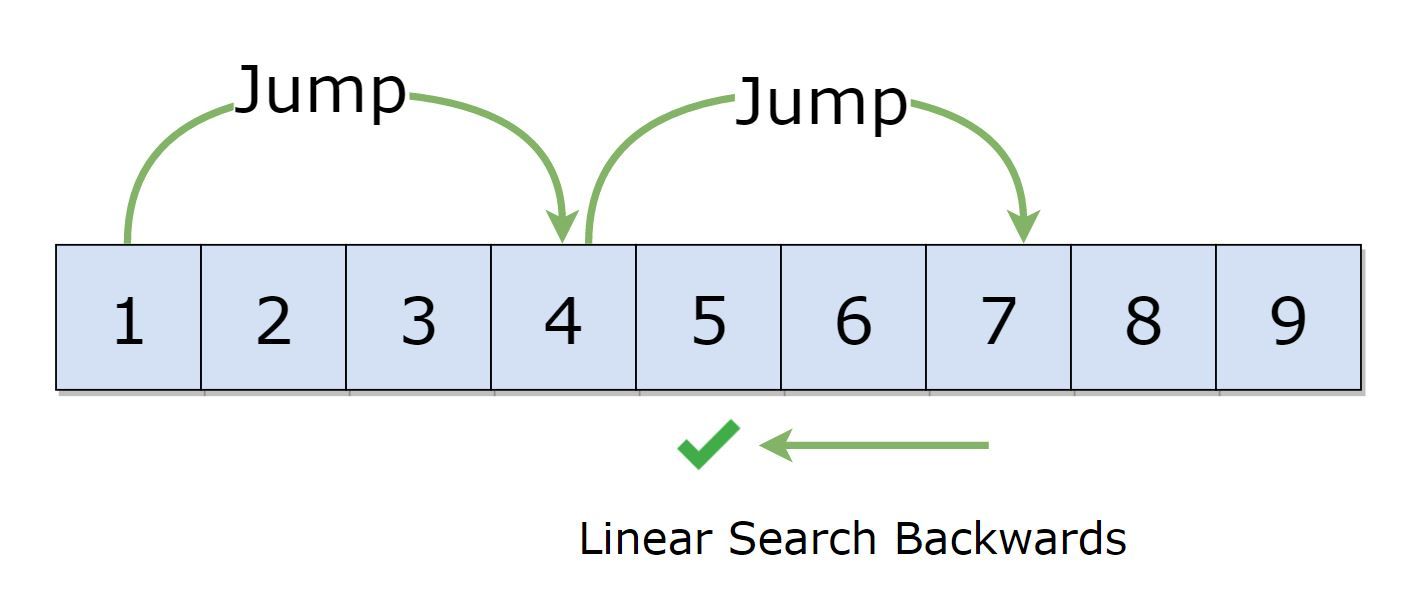
According to its performance, the jump search falls between linear search and binary search.
Time Complexity: O(√n)
Space Complexity: O(1)
Sorting Algorithms
Sorting is a widely studied concept in the Computer Science field. The idea of this algorithm is to arrange the items present in a list in a specific order. Every prime programming language comprises built-in sorting libraries.
When we have raw unstructured data(which is the case most times), we need to first sort the data before performing any operation on it. That’s when sorting algorithms play their part. Imagine if the dictionary wasn't sorted in the first place, you’ll have practically no way to locate a word in a short time.
That’s why sorting raw datasets is as important as collecting data in the field of computer programming. Sorting usually involves implementing numerical or alphabetical orders (ascending or descending).
Numerous sorting techniques are available in programming that ensure an excellent time complexity. Based on the requirements, the following are the important ones
- Insertion Sort
- Quick Sort
- Bucket Sort
- Heap Sort
- Count Sort
Insertion Sort
This technique works similarly to how we arrange cards in our hands in a card game. Taking the first card as a base, we place all the other cards either on the left or right depending on their value. This is an iterative process.
In an array, we assume the first element to be sorted. Then we compare all other elements with the first one. If an element is greater than the first one, it’s placed in front of the element. If it’s smaller, it’s placed behind the first element. We keep repeating this process until all the unsorted elements are placed in suitable positions.
Insertion sort works best when the array has a relatively lesser number of elements or when there are only a few elements left to be sorted.
Quick Sort
Imagine making a football team where all the defenders have to be taller than 6 ft. and all the strikers have to be below 6 ft. (just a hypothetical case). Then we’ll take 6 ft as the pivot value and make two groups around it, one for the below 6 ft people and the other one for above 6 ft.
In quick sort, a data structure is divided into sub-lists. An element is chosen to be the pivot value and all the other elements are divided into groups based on how much smaller or larger they are than the pivot value.
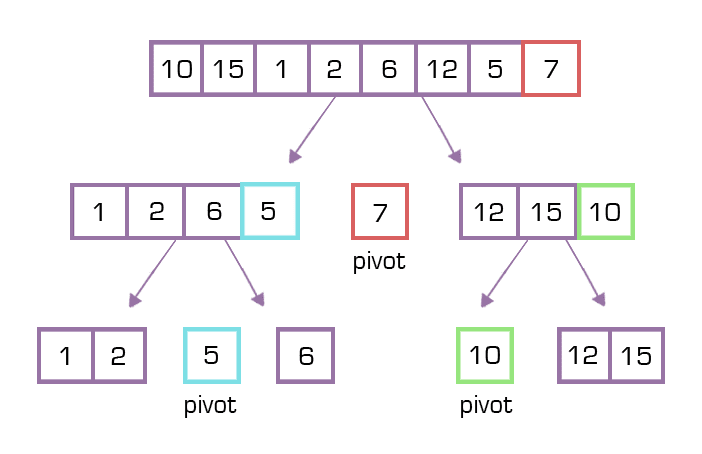
These sub-lists are then processed again until each has just one item, at which point the entire series will be arranged.
This is also called the divide-and-conquer method as we continually divide the data structure into smaller sub-lists and then process them individually.
Bubble Sort
This operates by going through each item in a list and, if necessary, switching neighboring items that are out of order. Up until there are no missing pieces in the list, the operation is repeated.
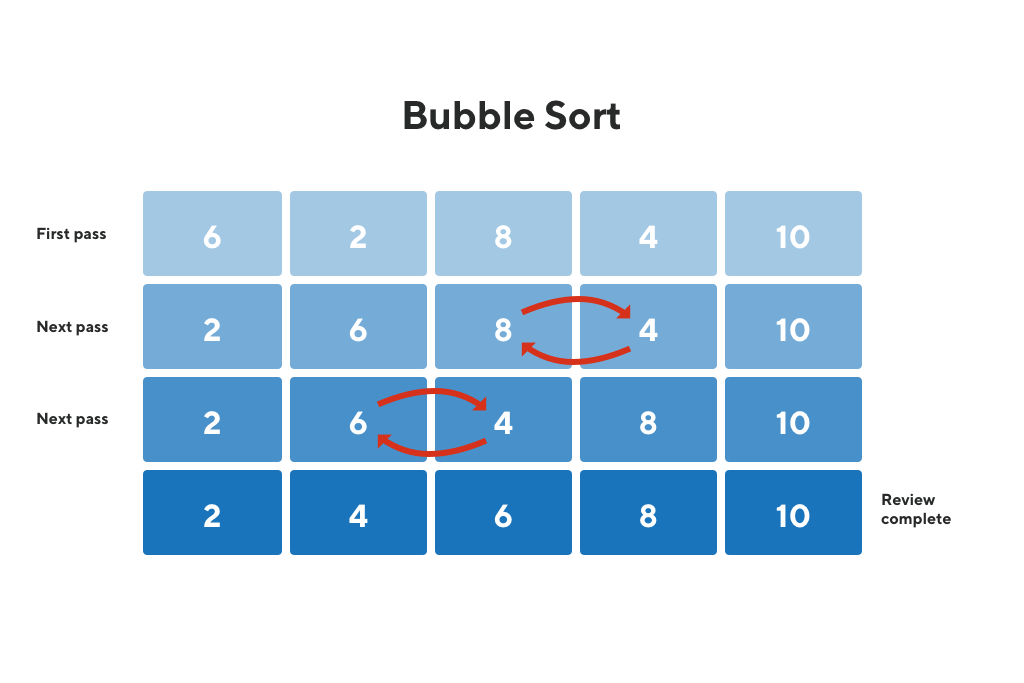
For instance, the procedure will iterate through the set until all the numbers are consistent with the desired numerical sequence, for a random numerical series that you wish to be organized in ascending order.
Merge Sort
Remember the ‘test papers’ example we mentioned in the beginning? That is a perfect example of merge sort.
Merge sort works on the divide and conquer approach, quite similar to quick sort. It repeatedly divides the given data into two equal halves and calls itself for each half again and again until there can be no more divisions i.e. the sub-list has only one element left.
After each sub-list has been sorted, it takes down the bottom-up approach and starts combining the sorted sub-lists together to get a sorted list or array. To do the merging, we must define the merge() function.
It is one of the most efficient and respected algorithms out there, as the worst-case complexity, in this case, is O(n log n).
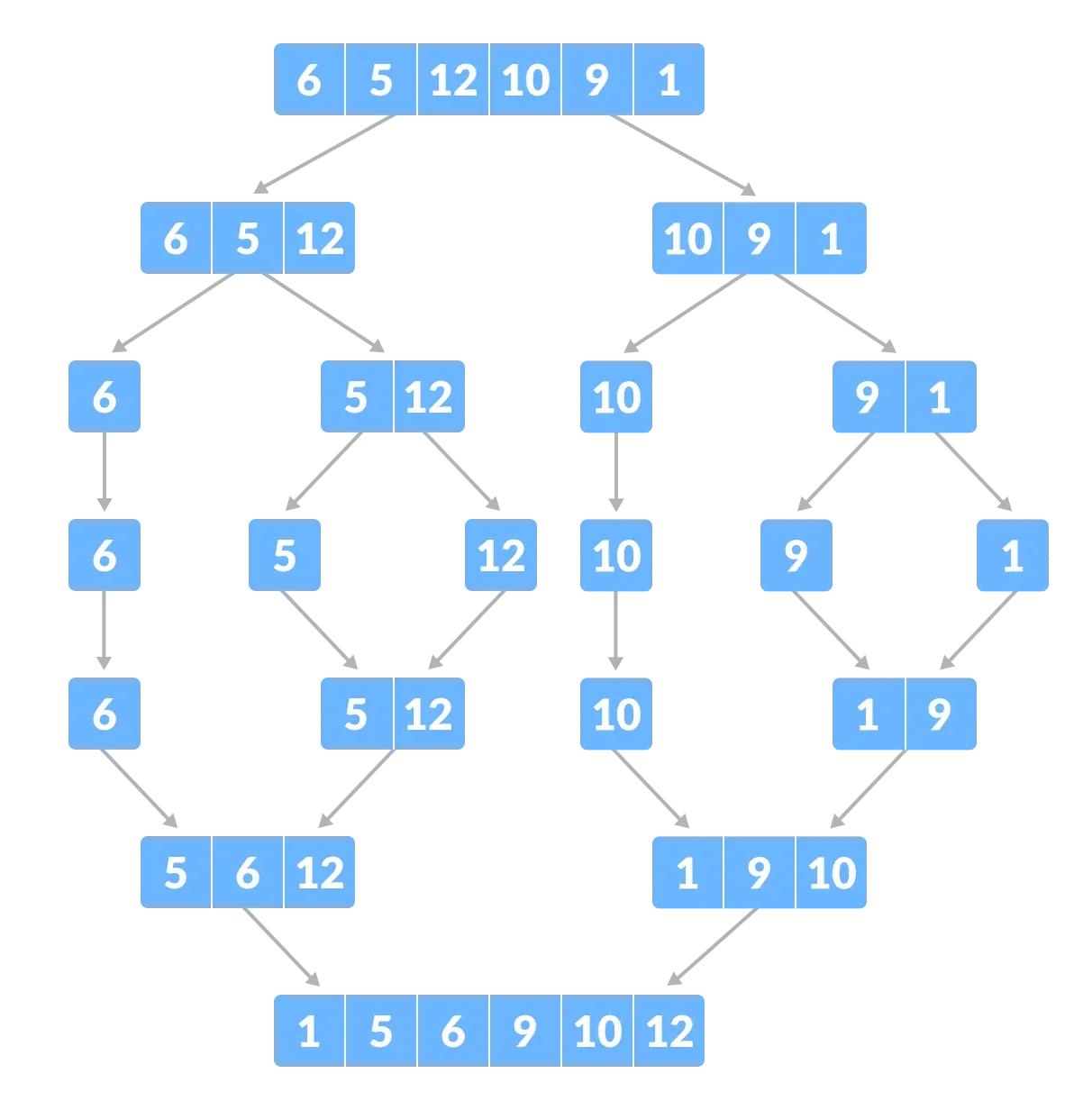
Despite both merge and quick sort working on the divide-and-conquer approach, there’s a fundamental difference between them.
Where merge sort divides the list into two equal sub-lists (different in size by 1 when the size of the list is odd), the partition doesn’t need to be of equal size in the case of quick sort. The divided sub-lists can be of any size depending on the pivot.
Graph Algorithms
Graphs are important data structures that can be used to model a variety of large-scale problems, having applications in state machine modeling, social networking sites, etc. where the number of searches is among millions and billions of data sets.
Graph algorithms are a set of instructions that performs operations like locating a node or finding the shortest path between two nodes in a graph. Here are some of the most important graph algorithms to keep in mind:
Breadth-First Search (BFS Algorithm)
This search algorithm traverses all the nodes at a single level/hierarchy before moving on to the next level of nodes. BFS algorithm starts at the first node (in this picture - 1) and traverses all the nodes adjacent to 1 i.e. 2 and 3. After all the nodes at the first level are traversed, it proceeds to the next level and repeats the same process.
For example - After vertices 2 and 3 are traversed, the BFS algorithm will then move to the first adjacent node of 2 i.e. 4, and traverse all its adjacent nodes. This goes on until all the nodes in the graph are searched.
Depth-First Search( DFS Algorithm)
The Depth-First search algorithm traverses the nodes in a vertical manner. It starts with the root node and traverses one adjacent node and all its child nodes before moving on to the next adjacent node.
Example - The algorithm will start with 1 and search all the nodes connected to 2 - 4 and 5, and then move to the next adjacent node to 1 i.e. 3. The order would be given as: 1 -> 2 -> 4 -> 5 -> 3.

Dijkstra’s Algorithm
Dijkstra algorithm is used to find the shortest path between two nodes in a graph data structure. Perhaps the most popular application of this algorithm is in Google Maps where we find the shortest distance between two locations.
It works on the principle- If A → E is the shortest path between two nodes A and E, and the sub-path B → E is a part of that path, then B → E is also the shortest possible sub-path between nodes B and C.
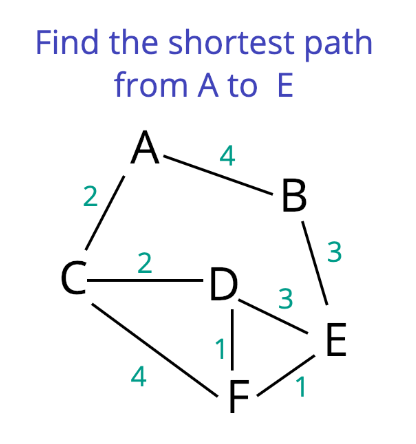
Dijkstra algorithm is also considered a single source shortest path algorithm, as we have only one source initially and we have to find the shortest path from the source to all nodes.
Here are a few more commonly-used algorithms to learn:
Huffman Coding Algorithm
This algorithm works best when there are frequently occurring characters in the data.
Huffman coding is a special technique developed by David Huffman. This algorithm compresses the data to reduce its size without losing any other details. Huffman coding is a data compression algorithm. This algorithm assigns variable-length codes to the input characters. The assigned codes’ lengths depend on the corresponding characters’ frequencies. The variable-length codes allocated to input characters are the Prefix Codes. This means that the bit sequences or the codes are allocated in a manner that the code allocated to a character is not the prefix of the code allocated to any other character. In this way, this algorithm ensures zero ambiguity while decoding the bitstream.
Let’s take the string below as an example-
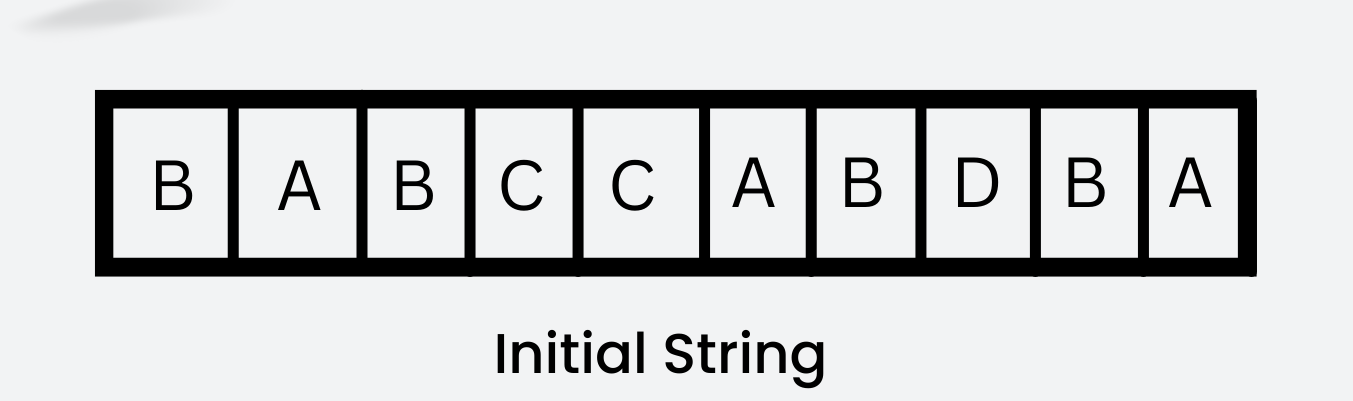
If each character occupies 8 bits and there are 10 characters in total, we’d need a total of 8*10 = 80 bits of memory to send this string over to the network. Using the Huffman Coding technique, we can reduce this memory.
For each character entered into this algorithm, a variable-length code is assigned. The frequency of character use affects the code length. The codes for the most common characters are the shortest, while the codes for the least common characters are longer. (
Hashing Algorithm
Hashing algorithms are also known as one-way programs. This algorithm makes the text scrambled in a manner that it cannot be decoded or read by anyone else – which is exactly the point. Hashing algorithms safeguard the data at rest. Thus, if a hacker tries to access to a server, then none of the data is readable. There are multiple hashing algorithms that exist, and each one works differently. It is also very important to note that encryption and hashing are two entirely different functions.
This is one of the most important algorithms today, the reason being it’s a cryptographic hash function. In today’s age when we get to handle and share huge volumes of data, hashing algorithms come as a savior.
Hashing converts arbitrary-sized data into fixed-size data (the hash value) from a given input. This hash value is nothing but a short summary of the data that represents its original form without making that original data known or accessible.
Case in point, imagine crumpling a paper document to the point that it's no longer readable. Hashing algorithm works in a similar fashion.
Once encoded, the hash value can’t be decoded and that’s why hashing technique is considered a one-way function. It is used for a variety of purposes including data organization, file integrity verification, etc.
Final Thoughts
So, these were the 12 most important and commonly-used algorithms in programming. We hope you’ve understood the basic idea behind each of these algorithms. And you must have also realized that we use most of these techniques in our day-to-day lives.
Without a doubt, learning DSA is detrimental to your aspirations of being a top-notch programmer. If you’re just beginning, you can refer to this article to understand the DSA concepts from scratch.
However, if you’re quite serious about making a career in software development and are looking for pathways, check out our part-time and full-time Full-Stack Web Development courses, starting at zero upfront fee. You’ll get to learn the industry-relevant tools & technologies and appear in numerous interviews in our placement cycles. Get on board to launch your career as a developer.
Cheers!
FAQs
What is the difference between a coder and a programmer?
The main activity for both programmers and coders is coding. However, programmers generally have a few more complex tasks that they need to perform. Coders typically have to write application codes in the programming language, a specific programming language, as instructed, while programmers also need to develop software functions and automation logic and resolve numerous problems.
What skills do programmers require?
The most important skills that a programmer must have are:
Mathematical skills: A general understanding of both arithmetic and algebra
Problem-solving: They should be able to solve various issues with the software.
Communication: They should be able to communicate with other team members.
Computer skills: Most programmers possess computer knowledge beyond the programming languages.