Applications of Queue Explained
Visitors who exceed the capacity of your website or app are transferred to a waiting room on a third party’s infrastructure. The waiting room then directs the customers who waited in line back to your website in the proper, sequential order at the throughput rate you configure.

Queues, often overlooked but incredibly powerful, play a pivotal role in various aspects of our digital lives. From handling customer service inquiries to optimizing traffic flows, queues silently streamline processes and enable efficient resource management.
In this blog, we discuss the diverse real-world applications of queue data structures that impact industries and systems we interact with daily.
A queue is a linear data structure that contains elements in an ordered sequence. It is an abstract data type, pretty similar to a stack data structure and also different fundamentally.
We insert data at one end of the queue and remove data from the other end.
Let’s take a look at one of the most basic applications of queues.
Think of a queue at the railway station ticket counter. The person standing first in the queue gets the ticket and leaves the group, while a new person joins at the back end of the queue.
This is at the center of the working of a queue, known as the First In First Out principle.
Here are a few more real-life applications of queues:
- Luggage checking machine
- Vehicles on toll tax bridge
- One way exits
- Patients waiting outside the doctor’s clinic
- Phone answering systems
- Cashier line in a store
We’ve already discussed the following topics in detail in our previous article:
- Types of Queue
- How does a Queue work
- Implementation of Queues
As we know, queues work on the principle of first come-first serve. What problems can be solved using that approach?
Here are some applications of queues
- CPU scheduling- to keep track of processes for the CPU
- Handling website traffic - by implementing a virtual HTTP request queue
- Printer Spooling - to store print jobs
- In routers - to control how network packets are transmitted or discarded
- Traffic management - traffic signals use queues to manage intersections
Now, let's look at some of them in detail-
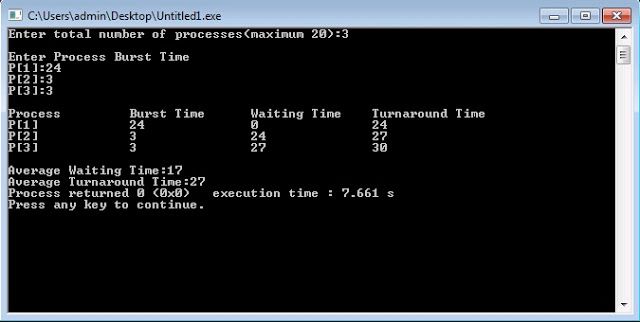
CPU Scheduling
This is one of the most common applications of queues where a single resource is shared among multiple consumers, or asked to perform multiple tasks.
Imagine you requested a task first before your friend, but your friend got the output first? Wouldn’t you call it a corrupt system? (quite literally!)
CPU page replacement algorithm doesn’t let that happen. It lets the operating system store all the processes in the memory in the form of a queue.
It makes sure that the tasks are performed on the basis of the sequence of requests. When we need to replace a page, the oldest page is selected for removal, underlining the First-In-First-Out (FIFO) principle.
Algorithm for the said function:
Start traversing the pages.
If a frame holds fewer pages than its full allocation capacity-
- Insert pages into the set one by one until the size of the set reaches capacity or all page requests are processed
- Update the pages in the queue to perform First Come-First Serve
- Increment page fault
Else
If the current page is present in the set, do nothing.
Else
- Remove the first page from the queue.
- Replace it with the current page in the string and store the current page in the queue.
- Increment page faults.
Return page faults.
This First Come First Serve (FCFS) method offers both non-preemptive and pre-emptive scheduling algorithms.
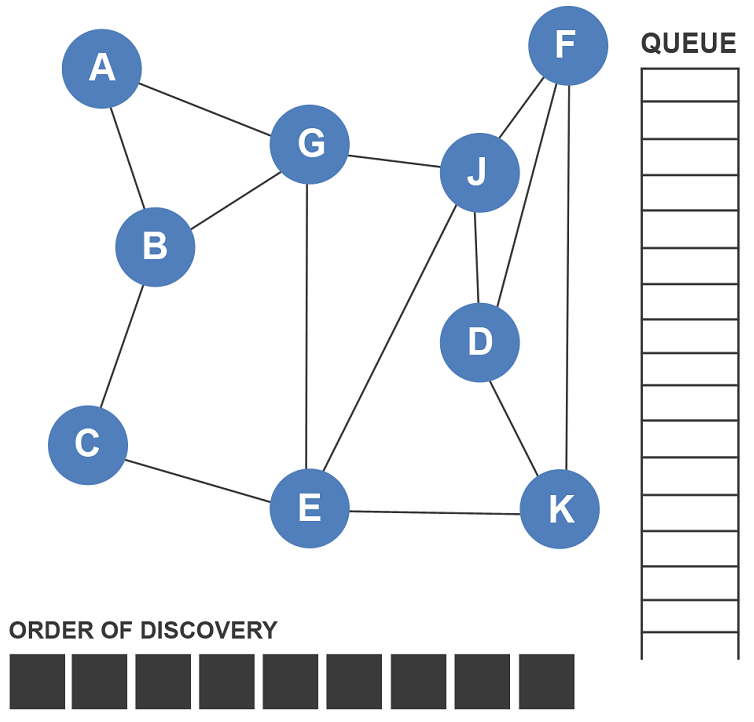
Breadth First Search Algorithm
This search operation traverses all the nodes at a single level/hierarchy before moving on to the next level of nodes. BFS algorithm starts at the first node and traverses all adjacent nodes before proceeding to the next level repeating the same process.
It uses the queue data structure to find the shortest path in the graph. In this method, one vertex is selected and marked when it's visited, then its adjacent vertices are visited and stored in the queue.
Here's the algorithm for the same:
Step 1: Set the status=1(ready state) for each node in G.
Step 2: Insert the first node A and set its status = 2(waiting state).
Step 3: Now, repeat steps 4 and 5 until the queue is empty
Step 4: Dequeue a node, process it, and set its status = 3(processed state)
Step 5: Insert all the neighbors of N that are in the ready state(staus=1) and set their status = 2(waiting state)
(END OF LOOP)
Step 6: EXIT
Printer Spooling
Another important example of applications of queues is printer spooling. Now, what do we mean by printer spooling?
It's crucial to understand from the outset that printers have much less memory than you might think. Even in this day and age, some only have a few megabytes of RAM available.
By using printer spooling, we can send one or more large document files to a printer without having to wait for the current task to be completed. Consider it as a cache or buffer. It's a location where your papers can "queue up" and prepare for printing when another printing activity has been finished.
All print tasks in the queue are managed by a program known as a "spooler". It will send the line of documents to the printer in the sequence they were received using the First In First Out principle of the queue.
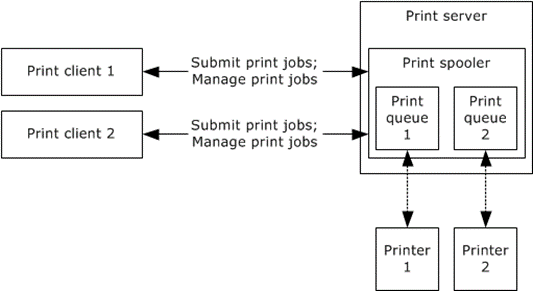
If not for spooling, each computer would have to manually wait for the printer to become accessible. Most people take it for granted because it's handled automatically in the background.
Spooling can make it simple to delete documents before they are printed because there is a queue in the order that they were received. You can choose to delete a particular job from the queue, for example, if you accidentally printed the wrong page or needed to format it slightly differently. While there could be several ways to accomplish this, queues provide the most efficient solution.
Handling Website Traffic
Increasing website traffic is the primary goal for websites. And why not, since more traffic means more engagement and more sales? However, extreme spikes in internet traffic frequently cause website infrastructure to fail. Particularly, the inventory systems and payment gateways are two of the most vulnerable systems needed to be preserved.
Another common concern is to ensure good user experience and fairness in terms of directing users from one webpage to another, in heavy-traffic situations.
One of the best website traffic management solutions is by implementing a virtual HTTP request queue, thus making it one of the most used applications of queues.
How does HTTP request queue work?
Visitors who exceed the capacity of your website or app are transferred to a waiting room on a third party’s infrastructure (Queue-it and Netprecept are a few of the industry-popular web traffic management solutions).
The waiting room then directs the customers who waited in line back to your website in the proper, sequential order at the throughput rate you configure.

The online queue informs users of wait durations and the number of individuals in front of them in the virtual line.
Routers in Networking
Routers are essential pieces of networking hardware that regulate how data moves within a network. The input and output interfaces on routers are where packets are received and transmitted.
A router might not be able to handle newly arriving packets because of its limited memory.
When the rate at which packets enter the router's memory exceeds the rate at which they leave, there will be issues. In this case, older packets will be deleted while newer packets will be ignored.
Therefore, to control how packets are kept or discarded as needed, routers must incorporate some form of queuing discipline into their resource allocation algorithms.
Following are a few queueing disciplines routers use to select which packets to keep and which ones to drop in times of congestion:
First-In-First-Out Queuing (FIFO)
Most routers' default queuing strategy is FIFO. This often requires minimal to no setup on the server. In FIFO, every packet is handled in the order that it enters the router. When the memory is full, new packets trying to enter the router are rejected (tail drop).
Such a system, however, is not appropriate for real-time applications, especially in crowded areas.
Prioritization of Queuing (PQ)
Instead of using a single queue, the router divides the memory into several queues according to some metric of priority in priority queuing. Following that, each queue is handled via FIFO, with each queue being cycled through one at a time. Depending on their priority, the queues are categorized as High, Medium, or Low. Always, the medium queue packets are processed after the high queue packets.
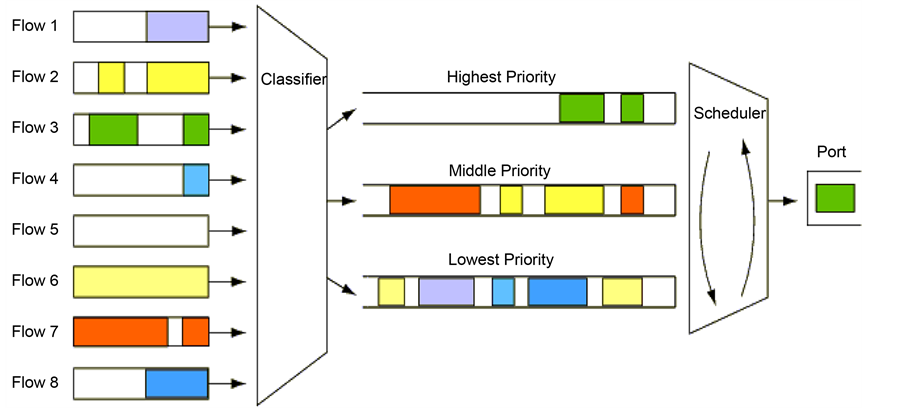
Fair Weighted Queuing (WFQ)
Based on traffic patterns, WFQ (Weighted Fair Queuing) creates queues and assigns bandwidth to them according to priority. The sub-queues bandwidths are dynamically assigned. Assume there are three active queues, each of which has a bandwidth percentage of 30%, 40%, and 60%.
Final Thoughts
So, these were the 5 primary applications of queues explained in detail. Refer to this article if you want to learn more about queue data structure.
If you’re a beginner and you want to learn the concept of data structures and algorithms from scratch, this article is a good place to start. You can also check out data analytics programs if you’re serious about making it your career. We at Masai offer a comprehensive program which is one of the top data analytics courses in India.
We at Masai have always kept a primary focus on training students in DSA in our part-time and full-time courses in full-stack web development. Students get to solve daily DSA problems and interview questions throughout the 30-week course.
If you want to become a full-stack developer and work in top companies, take the first step and check out these courses.
Cheers!
FAQs
What are the applications of circular queues in C?
Circular queues in C are used for efficient buffer management, printer spooling, task scheduling, and simulation modeling, facilitating seamless data processing and resource allocation in various applications.
What are some real-world applications of a queue data structure?
Real-world uses of queue data structures include call centers, printer management, traffic systems, task scheduling, and breadth-first search algorithms, enabling organized data handling and resource allocation.